| Text input | Ground-Truth | Ours | [HPMDubbing, CVPR23] | [StyleDubber, ACL24] |
|---|---|---|---|---|
it is finding your own voice where your own voice sits naturally and stably and healthily |
||||
squarespace makes it incredibly simple to create beautiful websites with their all in one platform |
||||
we do not need a european court |
||||
and any time i am passing it i stop and watch it too |
||||
now before you add those in if you want to have a little bit of a thicker soup what you will do |
||||
if you saw my video about the custom christian clings with a salmon dial you might remember that we spoke about mark cho the co founder of the armory co owner of drakes |
||||
for more videos on rpgs though just |
||||
he forgot me at the coffee shop when all i wanted to do was go and talk to him |
||||
and i am not sacrificing what |
||||
low prices can also give you a chance to practice your skills on people who do not expect huge outcomes or results because they know they are getting a deal |
||||
this older sister that she looks up to and that she sees as so successful and beautiful |
||||
but you still have a chance to make things right because i am here |
||||
i know what is on the other side |
||||
good luck and see you soon |
||||
if they are just wanting to conserve space they will probably just go with their phone |
||||
and they have that festival every year and it is supposed to celebrate like children |
||||
also be sure to subscribe to the channel for more and hit that bell icon so you get notified |
||||
i thought we were in the clear |
||||
i did it because i was foolish |
||||
you want that alien broad take her |
| Text input | Ground-Truth | Ours | [HPMDubbing, CVPR23] | [StyleDubber, ACL24] |
|---|---|---|---|---|
we had drawn a blank and it was not just iraq and afghanistan |
||||
i mean how do they form |
||||
they do not represent what our views are |
||||
we can do it 2 people together trying to improve trust |
||||
they were unexpected pleasures |
||||
but people did not relate to this |
||||
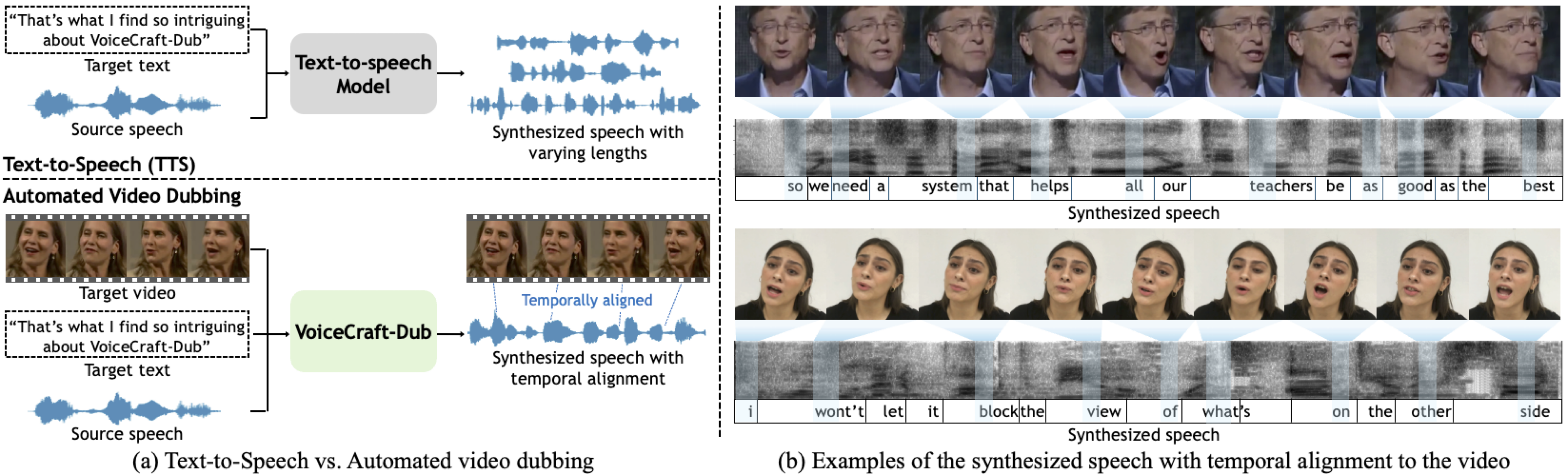
so we need a system that helps all our teachers be as good as the best |
||||
after college i desperately needed to find a place to call home |
||||
that is not simply critical to our economy |
||||
as an inventor i try and turn fantasy into reality |
||||
it took 6 days to deploy a global malware campaign |
||||
it turned out that we were doing a lot of low level drug cases on the streets just around the corner from our office in trenton |
||||
i have looked at the best and i have looked at some of the worst |
||||
they are the basis of every action that you take |
||||
imagine juggling a snowball across the tropics |
||||
when you grow up poor you want to be rich |
||||
has a coherent movement |
||||
it would skip a beat |
||||
the 2nd is you can put lots and lots of tests in a very small place |
||||
and this idea is actually nothing new |
||||
and it is hard and it takes courage but that is why we are alive right |
||||
and he said on the spot absolutely yes |
||||
sometimes it is messy and it is always unpredictable |
| Speaker sample & Text input | Ours | [HPMDubbing, CVPR23] | [StyleDubber, ACL24] |
|---|---|---|---|
|
but just imagine for a moment what this must feel like |
|||
|
but just imagine for a moment what this must feel like |
|||
|
but just imagine for a moment what this must feel like |
|||
|
but just imagine for a moment what this must feel like |
| Speaker sample & Text input | Ours | [HPMDubbing, CVPR23] | [StyleDubber, ACL24] |
|---|---|---|---|
|
i believe a story there has to be told |
|||
|
i believe a story there has to be told |
|||
|
i believe a story there has to be told |
|||
|
i believe a story there has to be told |
| Speaker sample & Text input | Ours | [HPMDubbing, CVPR23] | [StyleDubber, ACL24] |
|---|---|---|---|
|
and i said to myself i wanna get me one of them |
|||
|
and i said to myself i wanna get me one of them |
|||
|
and i said to myself i wanna get me one of them |
|||
|
and i said to myself i wanna get me one of them |
| Speaker sample & Text input | Ours | [HPMDubbing, CVPR23] | [StyleDubber, ACL24] |
|---|---|---|---|
|
that is the real world and unless we find a way to globalize democracy or |
|||
|
that is the real world and unless we find a way to globalize democracy or |
|||
|
that is the real world and unless we find a way to globalize democracy or |
|||
|
that is the real world and unless we find a way to globalize democracy or |
| Speaker sample & Text input | Ours | [HPMDubbing, CVPR23] | [StyleDubber, ACL24] |
|---|---|---|---|
|
we have to decide what it means |
|||
|
we have to decide what it means |
|||
|
we have to decide what it means |
|||
|
we have to decide what it means |
| Speaker sample & Text input | Ours | [HPMDubbing, CVPR23] | [StyleDubber, ACL24] |
|---|---|---|---|
|
it would be a mall and not a park |
|||
|
it would be a mall and not a park |
|||
|
it would be a mall and not a park |
|||
|
it would be a mall and not a park |
| Speaker sample & Text input | Ours | [HPMDubbing, CVPR23] | [StyleDubber, ACL24] |
|---|---|---|---|
|
so they won't go for a walk they won't hang out with their friends they won't eat |
|||
|
so they won't go for a walk they won't hang out with their friends they won't eat |
|||
|
so they won't go for a walk they won't hang out with their friends they won't eat |
|||
|
so they won't go for a walk they won't hang out with their friends they won't eat |